Microservices Data Design Patterns
This is the 5th post in a series on microservices architecture. This article is originally published at https://www.learncsdesign.com

Services in a microservices architecture should be loosely coupled so that they can be developed, deployed, and scaled independently. Microservices will each require different types of data and storage, so each will have its own database.
Database per service
Each microservice would have its own database, so they could choose how to manage data.
Benefits of having a database per service
- Loosely coupled
- Free to choose database types such as RDBMS like MySQL, wide-column databases like Cassandra, document databases like MongoDB, Key-Value stores like Redis, and graph databases like Neo4J.
Is it necessary to have a different database server for each service? That’s not a hard requirement. Let’s see what we can do.
If you are using an RDMS then the options are:
- Private tables per service — There is a set of tables owned by each service that must only be accessed by that service.
- Schema per service — Every service has a database schema that is private to it.
- Database server per service — Each service has its own database server.
Challenges of having a database per service
- Queries that need to join over multiple databases — The following data patterns will help us overcome this challenge.
- Event Sourcing
- API Composition
- Command Query Responsibility Segregation (CQRS)
2. Transactions across multiple databases — To overcome this challenge we have the Saga pattern.
Now let’s examine the different data patterns.
Event Sourcing
By means of event-sourcing, the state of a business entity is tracked by a sequence of state-changing events. A new event is added to the list of events whenever a business entity’s state changes. As saving an event is a single operation, it is inherently atomic. By replaying events, the application reconstructs an entity’s current state.
Applications persist events in an event store, which is a database of events. Events can be added and retrieved from the store using its API. The event store acts as a message broker as well. Services can subscribe to events through its API. When a service saves an event in the event store, it is sent to all interested subscribers. When entities have a large number of events, an application can periodically save a snapshot of an entity’s current state to optimize loading. The application finds the most recent snapshot and the events that have occurred since that snapshot to reconstruct the current state. This reduces the number of events to replay.

Benefits of event sourcing
- Using it solves one of the key challenges of event-driven architecture and makes it possible to reliably publish events when the state changes.
- It mostly avoids object-relational impedance mismatch problems since it persists events rather than domain objects.
- It provides a 100% reliable audit log of all changes made to an entity.
- It allows for the implementation of temporal queries that determine the state of an entity at any point in time.
- Business logic based on event sourcing involves loosely coupled entities that exchange events. This makes migrating from a monolithic application to a microservice architecture a lot easier.
Drawbacks of event sourcing
- There is a learning curve because it is an unfamiliar style of programming.
- Querying the event store is difficult since it requires a typical query to reconstruct entities states. Inefficient and complex queries are likely to result. Therefore, the application must implement queries using Command Query Responsibility Segregation (CQRS). In turn, this means that applications must handle eventually consistent data.
API Composition
You can implement query operations that retrieve data from multiple services by using the API composition pattern. In this pattern, a query operation is implemented by calling the services that own the data and then combining the results.
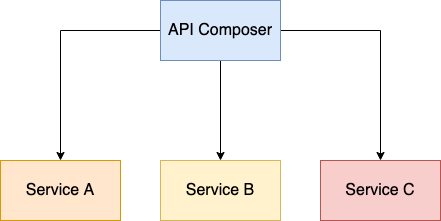
Benefits of API Composition
- This is a convenient way to query data in a microservice architecture.
Drawbacks of API Composition
- Occasionally, queries would result in inefficient, in-memory joins of large datasets.
Command Query Responsibility Segregation (CQRS)
An RDBMS is often used as the transactional system of record and a text search database such as Elasticsearch or Solr for text search queries. Some applications keep the databases in sync by writing to both simultaneously. Others copy data from the RDBMS to the text search engine periodically. The applications built on this architecture take advantage of the strengths of multiple databases, the transactional properties of the RDBMS, and the querying capabilities of the text database. CQRS generalizes this kind of architecture.
Microservice architectures face three common challenges when implementing queries.
- Data scattered across multiple services is retrieved using the API composition pattern, resulting in expensive and inefficient in-memory joining.
- Data is stored in a format or in a database that does not efficiently support the required query by the service that owns the data.
- Separating concerns means that the service that owns the data shouldn’t be responsible for implementing query operations.
All three problems can be solved by using the CQRS pattern.
The primary goal of CQRS is to segregate or separate concerns. Hence, the persistent data model is split into two parts: the command side and the query side.
Create, update, and delete operations are implemented by the command side modules and the data model. Queries are implemented by the query side module and data model. By subscribing to the events published by the command line, the query side keeps its data model synchronized with the command side
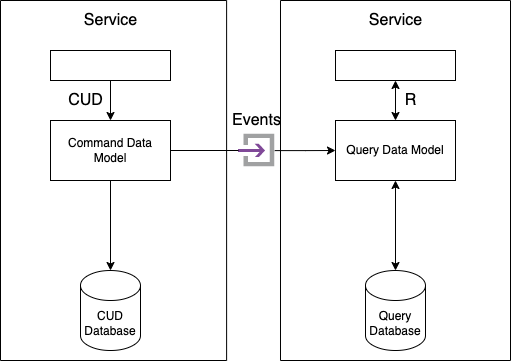
Benefits of CQRS
- Enable the efficient implementation of queries in a microservice architecture — If you use the API composition pattern to implement queries, you may experience expensive, inefficient in-memory joins of large datasets. For these queries, using a CQRS view that pre-joins data from two or more services are more efficient.
- Enables the efficient implementation of diverse queries — It is often difficult to support all queries using a single persistent data model. In CQRS, one or more views are defined that efficiently implement specific queries, eliminating the limitation of a single datastore.
- Makes querying possible in an event sourcing-based application — CQRS also overcomes an important limitation of event sourcing. An event store only supports queries based on primary keys. The CQRS pattern addresses this limitation by defining one or more views of the aggregates that are kept up-to-date by subscribing to the streams of events that are published by event-sourcing aggregates.
- Improves separation of concerns — Domain models and persistent data models do not support both commands and queries. CQRS separates the command and query sides of the service into separate code modules and database schema.
Drawbacks of CQRS
- More complex architecture — In order to update and query views, developers need to write query-side services. Different types of databases might be used by an application, which adds to the complexity for both developers and DevOps.
- Dealing with the replication lag — Between when an event is published from the command side and when it is processed by the query side and when the view is updated, there is a delay.
Saga Pattern
Using sagas, you can maintain data consistency in a microservice architecture without using distributed transactions. You define a saga for each command that updates data across multiple services. A saga is a series of local transactions. Local transactions update data within a single service using ACID transaction frameworks.
Sagas utilize compensating transactions to roll back changes. Imagine that the nth transaction of the saga fails. The previous (n-1)th transaction must be undone. As a result, total (n-1) compensating transactions would be initiated to roll back changes in reverse order.
Coordinating Sagas
In order for a saga to be implemented, it needs logic to coordinate its steps. As soon as a saga is initiated by the system command, the coordination logic must select and instruct the first saga to execute a local transaction. As soon as that transaction is complete, the sequencing coordination selects and invokes the next saga participant. The process continues until the saga is complete. If a local transaction fails, the saga must execute compensating transactions in reverse order.
There are a couple of ways to structure a saga’s coordination logic:
Choreography — Distribute decision-making and sequencing among the participants of the saga. They communicate mainly by exchanging events.
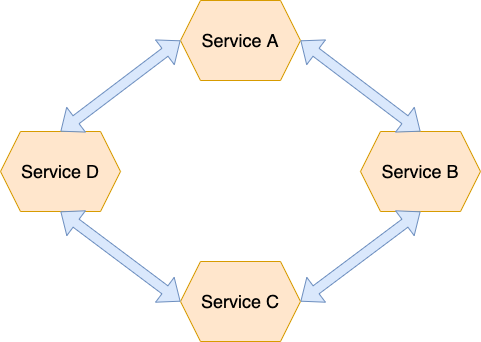
Benefits of Choreography based sagas
- Simplicity — When business objects are created, updated, or deleted, services publish events.
- Loose coupling — Events are subscribed to by participants who are not aware of one another.
Drawbacks of Choreography based sagas
- More difficult to understand — The choreography distributes the implementation of the saga among the services.
- Cyclic dependencies between the services — The saga participants subscribe to each other’s events, which often creates cyclic dependencies.
- Risk of tight coupling — Participants in the saga must subscribe to all events that affect them.
Orchestration — A saga’s coordination logic should be centralized in a saga orchestrator class. During a saga, an orchestrator sends command messages to participants telling them what operations they should perform.
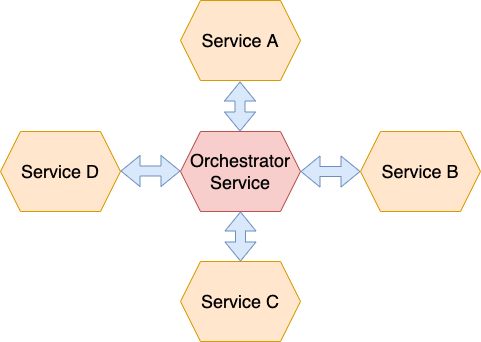
Benefits of Orchestration based sagas
- Simpler dependencies — Cyclic dependencies are not introduced.
- Less coupling — Services implement APIs that are called by the orchestrator, so it does not need to know about events published by saga participants.
- Improves separation of concerns and simplifies the business logic — In the saga orchestrator, saga coordination logic is localized. Domain objects have no knowledge of the sagas in which they are involved.
Drawbacks of Orchestration based sagas
- The risk of centralizing too much business logic in the orchestrator — If you design orchestrators that are solely responsible for sequencing and don’t contain any other business logic, you can avoid this problem.
Below are links to posts that explain each pattern in more detail.
1. Monolithic vs Microservices Architecture
2. Microservices Design Principles
3. Microservices Design Patterns
4. Microservices Decomposition Design Patterns
5. Microservices Data Design Patterns
6. Microservices Communication Design Patterns
7. Microservices External API Integration Patterns
8. Microservices Observability Design Patterns
9. Microservices Service Discovery Design Patterns
10. Microservices Cross-Cutting Concerns Design Patterns
11. Microservices Security Design Patterns
12. Microservices Deployment Design Patterns
If you like the post, don’t forget to clap. If you’d like to connect, you can find me on LinkedIn.
