Introduction to Stream Processing using Apache Flink — Part1

Stream processing is a programming paradigm that treats data streams or sequences of time-based events as the core input and output of computations, specifically focusing on continuous and limitless data.

Stream processing systems process events promptly upon arrival, often in small, incremental units known as events or records. This capability allows organizations to swiftly extract value from data, making it highly advantageous for time-sensitive applications and situations demanding real-time insights.
These stream processing systems excel in managing high-velocity, unbounded data streams, including click streams, log streams, live sensor data, social media feeds, event streams, transaction data, and IoT device data. The range of potential use cases for such systems is virtually limitless.

Stream processing frequently integrates state management to effectively handle continuous data streams. This state captures pertinent information necessary for subsequent event processing or assistance. State can take various forms, such as:
- Incremental Aggregates: These are calculations that evolve incrementally as new data arrives. They are used to continuously update summaries or statistics in real-time.
- Static Data: Static data represents information that remains constant over time and can be used to enrich or augment incoming data. It enhances the context and richness of the streaming data.
- Previously Seen Events: State can also include a record of previously processed events, allowing for contextual analysis and pattern recognition by referencing historical data.
Utilizing these different forms of state management enhances the capabilities of stream processing systems in handling dynamic and evolving data streams.

An effective stream processing system must have the capability to store data locally for rapid processing. Simultaneously, to ensure fault tolerance, the system periodically persists its state through a mechanism known as checkpoints to a durable and distributed file system. While stream processes are designed to run continuously, they are not immune to failures. Consequently, stateful stream processing involves the ongoing management and utilization of memory or historical data within the continuous stream of information.
This dual approach — local storage for speed and checkpoint-based persistence for reliability — enables stream processing systems to strike a balance between processing efficiency and fault tolerance, ensuring that they can handle both high-speed data streams and recover gracefully from potential failures.
In contrast to stateless processing, where each piece of data is treated in isolation, stateful processing leverages historical context to analyze, aggregate, detect patterns, join streams, or perform other advanced operations on the streaming data. This historical context enables more comprehensive and nuanced insights into the data’s behavior and trends.
Stream processing is a powerful tool for various sophisticated use cases that demand real-time decision-making. Some notable examples include:
- Fraud Detection: Identifying fraudulent activities in real-time, such as credit card fraud or unauthorized access.
- Supply Chain Updates: Keeping track of inventory levels, shipment statuses, and supplier interactions to optimize supply chain operations.
- Personalization: Tailoring content, recommendations, or user experiences based on real-time user behavior and preferences.
- Abandoned Cart Analysis: Analyzing shopping cart data in real-time to identify and recover potential sales that were abandoned during the checkout process.
- Anomaly Detection: Detecting unusual or unexpected patterns in data streams, which can be critical for system health monitoring, security, and quality control.
- Change Data Capture: Capturing and processing changes to databases or data sources in real-time, ensuring that downstream systems stay synchronized.
- Fleet Management: Monitoring and optimizing the operations of a fleet of vehicles or assets in real-time, enhancing efficiency and safety.
- Analytics at the Edge: Performing data analysis and decision-making directly on edge devices or sensors, reducing latency and enabling immediate actions.
These use cases demonstrate the versatility and real-time capabilities of stream processing, making it an invaluable technology for organizations seeking to gain actionable insights and respond swiftly to dynamic data environments.
Here are some specific example use cases that highlight the practical applications of stream processing:
- Real-Time Search and Recommendation Models (e.g., Amazon): Online marketplaces like Amazon use stream processing to analyze user behavior, product interactions, and real-time inventory updates to provide personalized product recommendations and search results.
- Building Real-Time Session Behavior Profiles of Users (e.g., Netflix): Streaming services like Netflix utilize stream processing to track user interactions, preferences, and content consumption patterns in real-time. This enables them to adjust content recommendations and user experiences dynamically.
- Real-Time Trade Settlement Dashboard (e.g., Zerodha): Financial institutions leverage stream processing to monitor market data, trade executions, and risk factors in real-time. It enables them to make timely trading decisions and manage settlements efficiently.
- Real-Time Revenue Accounting (e.g., Razorpay): Payment processing companies like Razorpay use stream processing to instantly process and reconcile financial transactions, ensuring accurate revenue accounting and fraud detection.
- Machine Learning-Based Anomaly/Fraud Detection (e.g., Banks): Banks employ stream processing for real-time monitoring of financial transactions to detect unusual or fraudulent activities. Advanced machine learning models are applied to identify anomalies and trigger alerts.
- Real-Time Data Refinement and Data Pipelines (e.g., Data Company): Data-driven organizations use stream processing to clean, transform, and enrich incoming data in real-time. This refined data is then fed into various data pipelines for analytics, reporting, or other downstream processes.
These examples showcase the diverse range of industries and applications where stream processing plays a pivotal role in enabling real-time decision-making, enhancing user experiences, and ensuring the efficient and secure operation of systems
A typical and fundamental use case for stream processing is the implementation of streaming data pipelines. In this scenario:

- Event Ingestion: Events are continuously consumed from a streaming storage layer, which can be a data source like message queues, log files, IoT sensors, or other streaming platforms.
- Data Processing: These incoming events are processed in real-time by different data pipelines. Each pipeline may perform various operations such as data transformation, enrichment, filtering, aggregation, or complex event pattern detection.
- Data Destination: After processing, the results or refined data can be forwarded to various destinations based on the specific requirements of the application. Common destinations include:
- Transactional Databases: Streamed data is inserted or updated in databases to maintain up-to-date records for further analysis, reporting, or transactional purposes.
- Search Indexes: Data is indexed in real-time to support efficient and immediate search capabilities, enhancing user experiences in applications like search engines or e-commerce platforms.
- Streaming Storage Layer: Processed data can be looped back to the streaming storage layer for additional analysis, retention, or as a data source for other downstream processes.
This use case illustrates the pivotal role of stream processing in orchestrating and optimizing the flow of data through an organization’s infrastructure. It ensures that data is continuously and efficiently processed, enabling real-time insights, decision-making, and seamless data integration across various systems and applications.
Streaming analytics is another highly popular and impactful use case for stream processing:
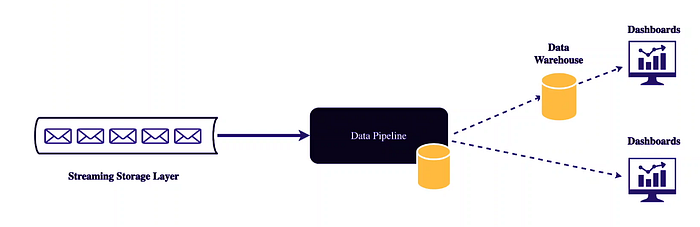
It revolves around the real-time analysis of data streams to extract valuable insights and drive dynamic dashboards that update in real-time. Here’s how it works:
- Real-Time Data Ingestion: Streaming analytics starts with the continuous ingestion of data streams from various sources, such as IoT devices, social media feeds, sensors, application logs, or other data producers.
- Data Processing and Analysis: Stream processing systems analyze incoming data in real-time. This analysis can involve a wide range of operations, including aggregation, filtering, pattern recognition, sentiment analysis, and machine learning-based predictions.
- Dashboard Updates: The insights generated from the analysis are immediately reflected in real-time dashboards. These dashboards provide a visual representation of the data, allowing users to monitor key metrics, trends, and anomalies as they happen.
- Alerts and Notifications: Streaming analytics systems can also trigger alerts or notifications when predefined conditions or thresholds are met. This proactive approach enables rapid responses to critical events or anomalies.
- Interactive Queries: Users can interactively query the streaming data to explore specific details or drill down into the data for deeper analysis. This ad-hoc querying capability empowers decision-makers to gain on-the-fly insights.
- Decision-Making: Real-time insights from streaming analytics support informed decision-making. Organizations can respond swiftly to changing conditions, emerging opportunities, or potential issues.
Streaming analytics is applied across various industries and use cases, including financial services, e-commerce, healthcare, industrial monitoring, and more. It provides a powerful tool for businesses and organizations to harness the value of real-time data, improve operational efficiency, enhance customer experiences, and make data-driven decisions in an ever-changing environment.
Machine learning integration with stream processing is of growing importance, especially as real-time machine learning becomes increasingly powerful and relevant:
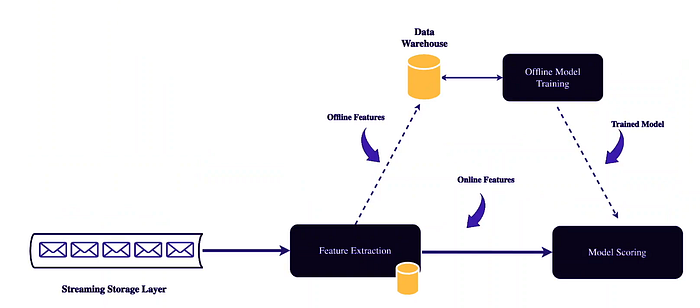
Stream processing enables organizations to perform real-time data extraction and model scoring, with the flexibility to combine it with offline training. Here’s how this synergy works:
- Real-Time Data Extraction: Stream processing systems continuously ingest and process data streams. This real-time data can include user interactions, sensor readings, transaction data, and more. It serves as the input for machine learning models.
- Model Scoring: Machine learning models are deployed within the stream processing pipeline to make real-time predictions or classifications based on the incoming data. These predictions can range from fraud detection to personalized recommendations.
- Dynamic Model Updating: Stream processing allows for the dynamic updating of machine learning models as new data arrives. This ensures that models adapt quickly to changing patterns and maintain their accuracy.
- Offline Training: In addition to real-time scoring, organizations can perform offline training of machine learning models using historical data. Stream processing systems can manage the training pipeline and seamlessly integrate updated models into the real-time processing flow.
- Ensemble Learning: Multiple machine learning models can be combined or ensembled within the stream processing pipeline to enhance predictive accuracy and robustness.
- Feedback Loops: Stream processing can capture feedback from model predictions and user interactions. This feedback can be used to continuously improve models over time.
- Real-Time Decision Support: The results of machine learning model scoring are often used to make real-time decisions, trigger actions, or provide recommendations within applications, such as fraud prevention, content personalization, or quality control.
The combination of stream processing and machine learning empowers organizations to harness the full potential of their data in real-time, providing actionable insights and supporting dynamic, data-driven decision-making. This synergy is particularly valuable in applications where immediate responses to data are critical, such as in finance, healthcare, e-commerce, and industrial operations.
Event-driven architecture and event-driven applications can derive significant benefits from stream processing.
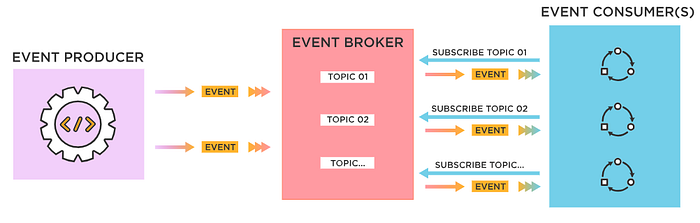
Here’s how stream processing enhances these architectural approaches:
- Real-Time Responsiveness: Stream processing provides the capability to react to events and messages in real-time. This real-time responsiveness is crucial for event-driven architectures where components need to react promptly to incoming events or signals.
- Scalability: Stream processing systems are inherently designed for scalability and can handle high-throughput event streams efficiently. In event-driven architecture, this scalability ensures that the system can handle an increasing number of events and maintain responsiveness.
- Complex Event Processing: Stream processing allows for complex event processing (CEP), enabling the detection of patterns, correlations, and anomalies in event streams. This is invaluable for event-driven applications that require intelligent decision-making based on event data.
- Distributed Event Processing: Event-driven systems often involve distributed components and microservices. Stream processing systems support distributed event processing, ensuring that events are processed across distributed nodes seamlessly.
- Event Enrichment: Stream processing can enrich events with additional context or data from various sources, enhancing the richness and relevance of events before they trigger actions or updates in event-driven applications.
- State Management: Stateful stream processing is conducive to managing the state associated with events in event-driven architectures. It enables the maintenance of stateful information, such as session data or event history, which can be vital for event processing.
- Event Routing: Stream processing can route events to the appropriate components or microservices based on rules, conditions, or content. This dynamic event routing supports the decoupling of event producers and consumers.
- Integration: Stream processing systems often offer connectors and integration capabilities with various event sources and sinks. This simplifies the integration of event-driven applications with external systems and services.
- Fault Tolerance: Stream processing systems are designed to be fault-tolerant, ensuring that event-driven applications remain robust even in the face of failures or disruptions.
- Event Correlation: Stream processing enables the correlation of related events and the generation of higher-level event abstractions, which can be valuable for making sense of complex event data.
Event-driven architectures and applications are instrumental in building responsive, scalable, and loosely coupled systems. When combined with stream processing, they gain the ability to process, analyze, and respond to events in real-time, unlocking new possibilities for automation, monitoring, decision-making, and user experiences across a wide range of domains, including IoT, telecommunications, finance, and more.
All of these use cases and more can be implemented with a sophisticated stream processing system such as Apache Flink.
Let’s learn more about what Apache Flink is:
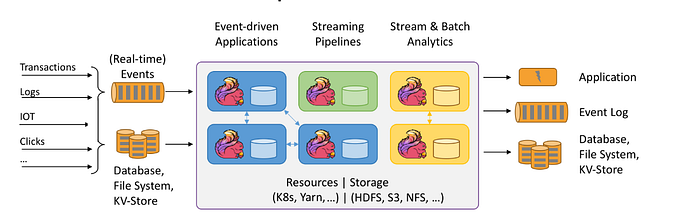
Apache Flink is a versatile and powerful stream processing system that empowers a wide range of use cases and applications. By harnessing its capabilities, you can unlock the potential of real-time data processing and analytics, making it an invaluable tool in the world of data engineering and analytics.
At its core, Apache Flink serves as a framework for executing stateful computations on both unbounded and bounded data streams. This means it can handle data that flows continuously, as well as data in batches, making it suitable for a variety of data processing scenarios.
Here’s a more detailed breakdown of Apache Flink’s key features and functionalities:
- Stream Processing with Data Stream API — Apache Flink offers a low-level Data Stream API that allows you to work with data streams, manage state, and handle event time processing. This API is particularly useful when you need fine-grained control over your stream processing logic.
- Relational APIs for Stream Processing — For those who prefer a more structured and SQL-like approach to stream processing, Flink provides higher-level relational APIs. You can choose between the Table API and Flink SQL to perform complex streaming analytics tasks. These APIs enable you to express your data transformations and analysis using familiar SQL-like queries.
- Batch and Streaming Unified APIs — Flink boasts the unique capability of providing unified APIs for both batch and streaming data processing. This means that you can write queries and transformations once and execute them seamlessly on both batch and streaming data, ensuring consistent results and reducing development complexity.
- Event-Driven Applications with Stateful Functions API — If you’re building event-driven applications within serverless architectures, Apache Flink’s Stateful Functions API comes to the rescue. This runtime environment allows you to define and execute your processing logic with ease. You can implement this logic using various programming languages, including Java, Python, Go, and even Rust (thanks to the Rust SDK).
- Dynamic Message Routing and Consistent State Management — Stateful Functions in Flink offer dynamic message routing capabilities, enabling efficient communication between different components of your application. Moreover, it supports consistent state management, eliminating the need for external databases to maintain application state. This simplifies the architecture and enhances the reliability of your stream processing applications.
Let’s delve into the distinctions between batch processing and stream processing, both of which are supported by Apache Flink.
These differences highlight the unique characteristics and requirements of each approach:
Batch Processing:
- Staged Execution — In a batch processing system, execution occurs in discrete stages. Data is collected, processed, and analyzed in well-defined, finite steps. Each stage is typically completed before moving on to the next.
- Pre-sorted Input — Batch processing often benefits from having input data that can be pre-sorted, for example, by timestamps or other relevant criteria. This pre-sorting can optimize the processing pipeline.
- Reporting After Completion — In batch processing, results are typically reported after the entire processing job is finished. This means that you may need to wait until all data has been processed before obtaining the final results.
- Failure Recovery — Dealing with failures in batch processing systems is relatively straightforward. If a failure occurs, the batch job can be easily restarted from the last completed checkpoint or from the beginning of the job. This provides a level of fault tolerance.
Stream Processing:
- Continuous Execution — Stream processing systems, in contrast, require a continuous execution pipeline. Data is processed as it arrives, and the processing pipeline must be up and running continuously to handle real-time data.
- Real-time Input — Stream processing systems accept data as it is generated or arrives in real-time. There’s no expectation that data will be pre-sorted or ordered by any specific criteria.
- Incremental and Immediate Reporting — Results in stream processing are reported as soon as they become available. This allows for real-time insights and immediate reactions to incoming data, making it well-suited for applications where low latency is critical.
- Robust Failure Handling — Stream processing systems require robust mechanisms for handling failures. Since they operate continuously, a failure can disrupt real-time data processing. Techniques like checkpointing, state management, and failover mechanisms are essential to ensure fault tolerance and data consistency.
Apache Flink has emerged as a solution to address some of the most challenging problems in the realm of data processing and stream computing.
Let’s explore these achievements and key aspects of Apache Flink:
- High Availability — Apache Flink ensures high availability through an “always on” and “always connected” infrastructure. This means that Flink applications are designed to keep running continuously, minimizing downtime and ensuring reliable data processing.
- Performance — Flink is designed for scalable performance, capable of handling low-latency, high-throughput demands. This performance scalability is vital for processing large volumes of data in real-time without compromising speed or efficiency.
- State — One of Flink’s strengths is its ability to manage state in a fault-tolerant manner. It ensures that the application’s state survives failures and restarts, maintaining data integrity and consistency throughout the processing pipeline.
- Time — Flink provides the capability to understand when all data for a specific timeframe has been processed. This feature is essential for applications that require synchronized or windowed processing of data across various time intervals.
Summary:
- Apache Flink is an open-source stream processor that offers several key advantages:
- It provides fault tolerance with precisely-once stateful operations, ensuring data consistency.
- It supports event time processing for both streaming and batch data, allowing for accurate temporal data analysis.
- Apache Flink boasts a highly scalable and performant runtime, capable of handling real-time data workloads.
- It offers a variety of layered APIs tailored to different use cases.
- Apache Flink has a rich ecosystem of connectors, making it easy to integrate with various data sources and sinks.
- It efficiently handles batch workloads through its unified batch and streaming APIs.
In next post we will discuss Apache Flink architecture and runtime in detail.
