An overview of distributed systems architectures
This is the 2nd post in a series on System Design. This article is originally published at https://www.learncsdesign.com
If 50% of a code executes serially, the rest in parallel, adding more than 8 cpu cores has essentially no effect.
— Amdahl’s law
The majority of massive-scale systems begin small and grow as they succeed. A typical very simple software architecture consists of a client tier, an application service tier, and a database tier.

Scaling Systems
Scaling out involves replicating a service in the architecture and running multiple copies on multiple servers. If we have N replicas and R requests, each server node processes R/N requests if we have N replicas and R requests. An application’s capacity and scalability can be increased with this simple strategy.
Scaling out an application requires two fundamental design elements.
- A load balancer — User requests are sent to a load balancer, which selects a service replica target to handle the request.
- Stateless services — For load balancing to be effective, the load balancer must be able to send consecutive requests from the same client to different service instances. API implementations in the services must not retain any state associated with individual clients.
In theory, scaling out allows you to add more (virtual) hardware and services to handle increasing request loads and keep request latencies low. When latencies rise, you deploy another server instance. Since stateless services don’t require code changes, they are relatively inexpensive — you only have to pay for the hardware.
Another highly attractive feature of scaling out is its availability. In the event that one of the services fails, the requests it is processing will be lost. As the failed service does not manage the session state, these requests can be reissued by the client and sent to another instance of the service. By doing so, the application is resilient to failures, thereby improving its availability.
Adding new service instances expands the request processing capacity infinitely. There will be a decline in the ability of your single database to provide low-latency query responses. Clients will experience longer response times if queries are slow. In the case of requests arriving faster than they are being processed, some system components will become overloaded and fail due to resource exhaustion, resulting in exceptions and request timeouts for clients. To scale your application further, you must engineer a way around the bottleneck created by your database.

Scaling the Database with Caching
By increasing the number of CPUs, memory, and disks in a database server, you can scale a system. A common database scalability strategy is scaling up.
It is highly effective to query the database as infrequently as possible from your services in conjunction with scaling up. Scaled-out service tiers can achieve this through distributed caching. Cache stores recently retrieved and frequently accessed database results in memory so they can be retrieved quickly without affecting the database.
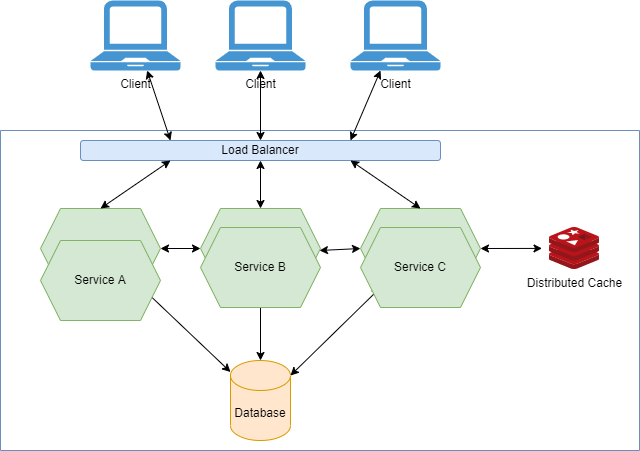
In the case of data that is frequently read but rarely changed, your processing logic can be modified to check a distributed cache first, such as a Redis store. You must also modify your processing logic to check for cached data when introducing a caching layer. Your code must still query the database and load the results into the cache as well as return them to the caller if what you want is not in the cache. Additionally, you need to decide when to remove or invalidate cached results.
Scaling a system can be made easier with a well-designed caching scheme. Caching is great for data that rarely changes and is frequently accessed.
Distributing the Database
There are two major categories for distributing the database:
- Distributed SQL stores — Organizations can scale out their SQL databases relatively seamlessly by storing the data across multiple disks and querying it through multiple replicas of the database engine. NewSQL stores generally fall into this category. NewSQL is a class of relational database management systems that provide the scalability of NoSQL systems while maintaining ACID guarantees of traditional databases. Among them are Amazon Aurora, CockroachDB, etc.
- Distributed NoSQL stores — Data is distributed across multiple nodes running the database engine, each with its own locally attached storage, using a variety of data models and query languages. Among them are Cassandra, MongoDB, etc.
In a distributed database, storage nodes can be added as the volume of data grows. In order to ensure the processing and storage capacity of each node is equally utilized, data is rebalanced across all nodes as nodes are added/removed.
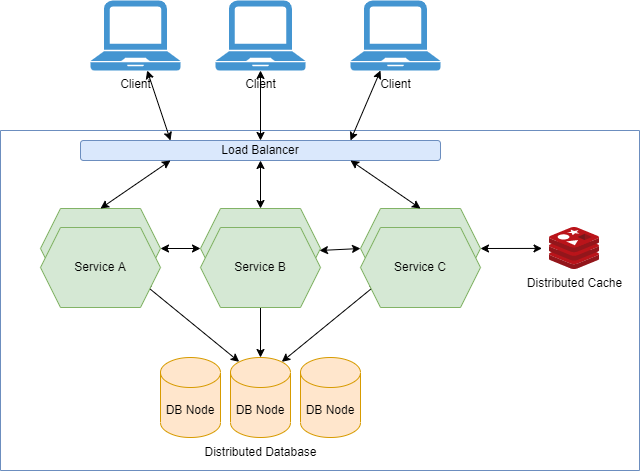
Availability is also enhanced by the distributed database. Data storage nodes can be replicated so that if one fails or cannot be accessed due to network issues, another copy is available.
Increasing Responsiveness
The majority of client application requests expect a response. A client sends a request and waits for a response. Request response time refers to the time between sending the request and receiving the result. Caching and precalculated responses can reduce response time, but many requests will still require database access.
Data can be reliably sent from one service to another using distributed queueing platforms. Among them are Kafka, RabbitMQ, etc. When a message is written to a queue, it is typically acknowledged much faster than if it were written to a database. A second service reads messages from the queue and writes them to the database.
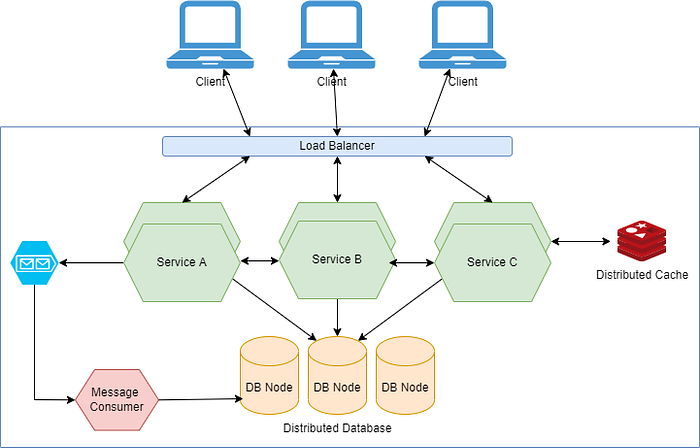
Whenever a write operation’s results are not immediately needed, an application can use this approach to improve responsiveness and scalability. All of these queueing platforms support asynchronous communication. A producer writes messages to the queue, which acts as temporary storage, while another consumer service removes messages from the queue and updates the database. Data must eventually be persisted. The concept of Eventually typically refers to a few seconds at most, but use cases that utilize this design should be able to handle longer delays without affecting the user experience as much.
I have written a detailed post on message-oriented middleware using RabbitMQ that you might find interesting.
Systems & Hardware Scalability
Even the most carefully crafted software architecture and code won’t be able to scale if the hardware is insufficient. There are some cases when increasing the number of CPU cores and available memory won’t increase scalability. A node with more cores will not improve performance if the code is single-threaded. In the same way, if multi-threaded code contains many serialized sections, only one thread can proceed at a time to ensure that the results are accurate.
Based on Amdahl’s law, we can calculate the theoretical acceleration of code when adding more CPU cores.
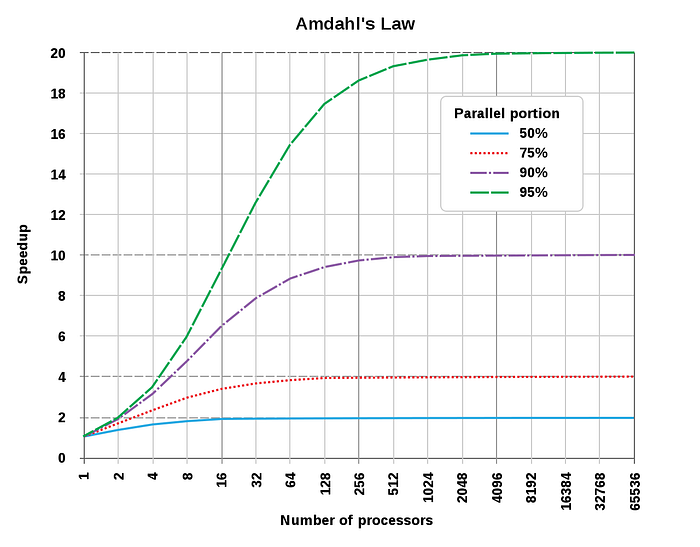
If a program needs 20 hours to complete using a single thread, but a one-hour portion of the program cannot be parallelized, therefore only the remaining 19 hours execution time can be parallelized, then regardless of how many threads are devoted to a parallelized execution of this program, the minimum execution time cannot be less than one hour. Hence, the theoretical speedup is limited to at most 20 times the single-thread performance.
— Wikipedia
Conclusion
These major approaches can be used to scale out a system as a collection of SOA/microservices and distributed databases.
If you like the post, don’t forget to clap. If you’d like to connect, you can find me on LinkedIn.
References
Book: Fundamentals of Software Architecture: An Engineering Approach
Book: Foundations of Scalable Systems
